WordPressは翻訳関数というのを用意していて、それを使えばpoファイル、moファイルによってタイトルや説明文を多国籍言語で表示させることができます。import { __ } from '@wordpress/i18n';とライブラリがインポートされているぐらいだから、手軽に使えるものと思い込み、いつでもマスターできると思っていました。
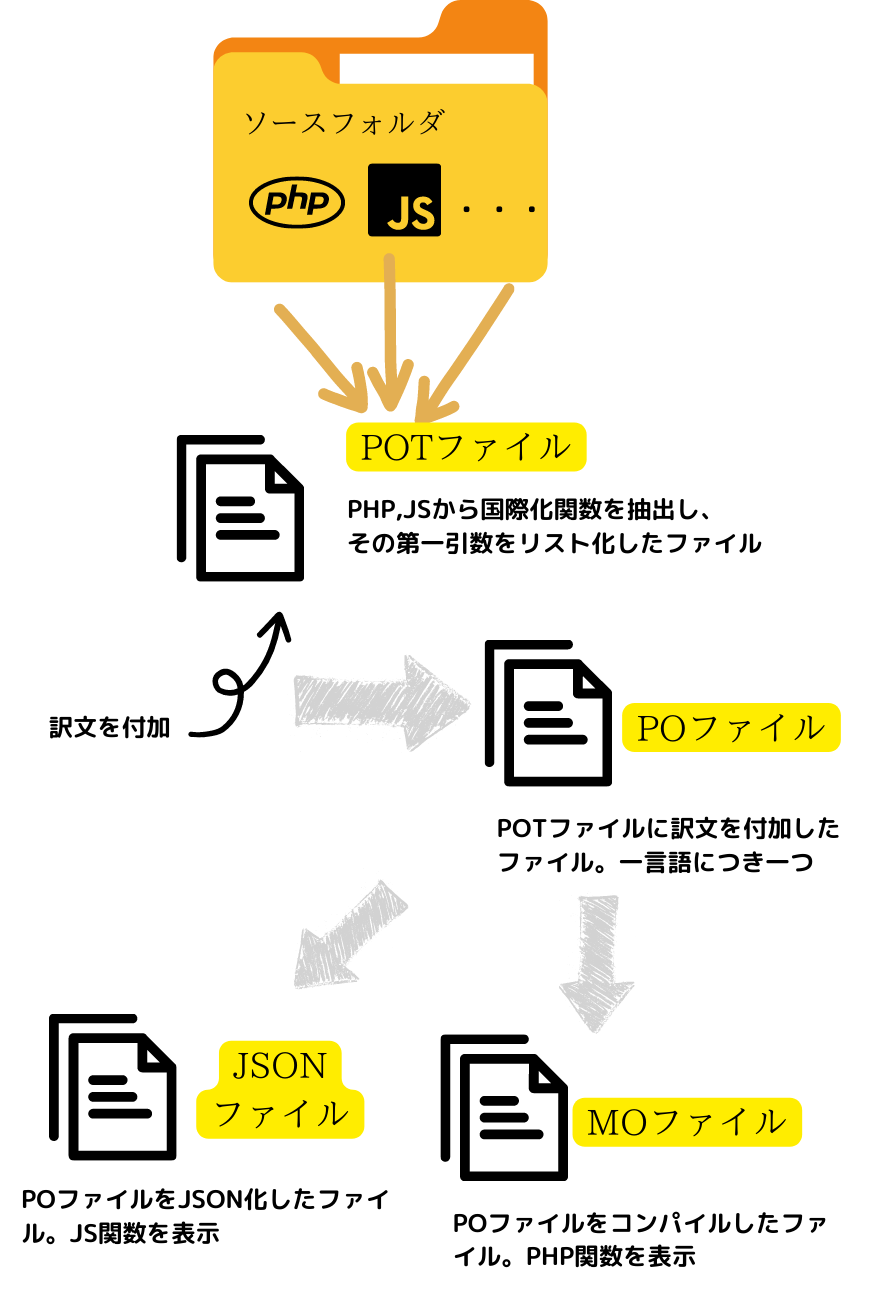
まず、この図をご覧ください。
とりあえず、この図で大まかなイメージを掴んでおいてください。
まず、POTファイルです。「プロジェクトのソースフォルダからプログラムファイルを検索し、その中から()や_e()などの翻訳関数を抽出し、その第1引数をリスト化したファイル」
さらに詳しく説明します。
とにかく、この関数がプラクラム内で使用されていることが前提になります。POTファイルは、その関数の第1引数、つまり、翻訳すべき原文のリストなのです。そして、それに訳文を入力する「枠」がついていますが、POTファイルの段階では、その部分が空なのです。
なぜ空かというと、それがまさにテンプレートと言われる所以で、そのPOTをもとに日本語訳のついたファイル、中国語訳のついたファイルというように複数のPOファイルを作るためです。
ということで、POTファイルは国際化対応の根幹となるファイルだと思います。これを確実に作ることから始めるべきだと思いました。
WP-CLIはWordPressのよくある作業を管理するための開発者向けのコマンドラインツールです。このツールでPOTファイルを作ります。
WP-CLIのインストールは次の手順で簡単にできます。
PowerShellを管理者権限で開きます。
以下のコマンドを実行して、Scoopをインストールします:
Set-ExecutionPolicy RemoteSigned -scope CurrentUser
iex (new-object net.webclient).downloadstring('https://get.scoop.sh')
コピー
PowerShellを開きます。
以下のコマンドを実行して、WP-CLIをインストールします:
インストールが完了したら、コマンドプロンプトやPowerShellでwp –infoを実行して、正しくインストールされたか確認できます。
対象のブロックのルートディレクトリでターミナルを開いて、次のコマンドを実行します。
wp i18n make-pot ./ languages/itmar_guest_contact_block.pot --exclude=node_modules/*
コピー 第1引数./はルートディレクトリ以下のすべてのディレクトリ内のファイルを対象に関数を検索することを意味します。
ということで実際に出来上がったファイルは以下のようになります。
・・・
#: guest-contact-block.php:163
msgid "Receipt processing completed successfully."
msgstr ""
#: build/index.js:132
#: src/edit.js:103
#: build/index.js:116
msgid "Inquiry information notification email"
msgstr ""
・・・
コピー このコードはPOTファイルの一部です。msgidが原文の見出しで、msgstrが訳文の見出しです。訳文は空になっていますね。#:以下は翻訳関数があったファイルとその行番号です。この情報が非常に重要なのです。これがないと、JSONファイルの作成のところで大きくつまづきます。
ここでPoeditというアプリケーションを使います。
このファイル名は重要です。デフォルトでは「ja.po」となっているので、その前に「テキストドメイン-」と入れます。__()等の第2引数に設定すると説明しました。そうすることによって翻訳関数はそのテキストドメインの文字列を含むファイル名を持つファイルから、第1引数にセットした原文の文字列から訳文を検索するようになっているのです。つまり、
__("Notification email subject", 'itmar_guest_contact_block')
コピー という関数があるとするとitmar_guest_contact_blockという名前を含むファイルを探し、さらに、第1引数の文字列と一致する訳文を探して表示するのです。ですから、ここでつけるファイル名は重要です。これを間違うと訳文は表示されません。
これで保存すれば無事にPOファイルは出来上がりです。
ではMOファイルは何のためにあるのでしょう。MOファイルはPHPの翻訳関数の訳文を表示させるファイル だということです。Javascriptの翻訳関数による訳文はMOルがあっても表示されません。
とりあえず、ここではMOファイルによる訳文の表示に絞って解説していきます。
load_plugin_textdomainによる読込
そしてさらにブロックのエントリポイントのPHPファイルに次のように記述しなくてはいけません。
function itmar_contact_block_block_init() {
・・・
//PHP用のテキストドメインの読込(国際化)
load_plugin_textdomain( 'itmar_guest_contact_block', false, basename( dirname( __FILE__ ) ) . '/languages' );
}
add_action( 'init', 'itmar_contact_block_block_init' );
コピー WordPressのinitアクションフックでload_plugin_textdomain実行するわけです。第1引数はテキストドメイン、第3引数はMOファイルの保存フォルダへの相対パスです。今回はブロックのルートディレクトリ直下のlanguagesフォルダを指しています(第2引数はあまり気にせずfalseでいいようです。)。
これでPHPで記述された翻訳関数の部分は訳文が表示されます。load_plugin_textdomainで、その場所を指定する必要がありますが、.\wp-content\languages\pluginsというフォルダに保存すれば、load_plugin_textdomainでの指定は必要ありません。
プラグインのエントリポイントのPHPファイルにはコメントヘッダーが付いていて、これがあることでプラグイン名等が表示されます。
/**
* Plugin Name: Guest Contact Block
* Plugin URI: https://itmaroon.net
* Description: A block with an email submission form.
* Requires at least: 6.1
* Requires PHP: 7.0
* Version: 0.1.0
* Author: Web Creator ITmaroon
* License: GPL-2.0-or-later
* License URI: https://www.gnu.org/licenses/gpl-2.0.html
* Text Domain: itmar_guest_contact_block
* Domain Path: /languages
*/
コピー こんな感じになっていますが、WP-CLIでPOTファイルを作ると、次のように抽出してくれます。
#. Plugin Name of the plugin
msgid "Guest Contact Block"
msgstr ""
#. Plugin URI of the plugin
msgid "https://itmaroon.net"
msgstr ""
#. Description of the plugin
msgid "A block with an email submission form."
msgstr ""
#. Author of the plugin
msgid "Web Creator ITmaroon"
msgstr ""
コピー この部分については翻訳関数がセットされていなくても、POファイルに訳文を入れてMOファイルを生成するだけで翻訳されます。
ここまでの手順も相当複雑でしたがPOT、PO、MOの各ファイルの機能を理解していれば、そんなに苦労せずにたどり着けるのではないかと思います。
そもそも、PHPの関数とJS(JavaScript)の関数で翻訳の仕組みが違い、しかも、MOファイルではなくJSONファイルを用意しないといけないなんて思いもしませんでした。
それはともかく、コードとしては次のようになっています。
import { __ } from '@wordpress/i18n';
・・・
return(
・・・
<TextControl
label={__("Notification email subject", 'itmar_guest_contact_block')}
・・・
/>
・・・
)
コピー PHPと違うのは関数のimportが必要であるという点だけです。
wp i18n make-json languages/ --no-purge
コピー これでプラグインのルートディレクトリ直下のlanguagesフォルダからpoファイルを探し出してjsonファイルが生成されます。
wp_set_script_translationsによるJSONファイルの指定(失敗談)
PHPではload_plugin_textdomainでMOファイルを読み込みましたが、JSONファイルにおいてもそれと同様のプロセスが必要です。
wp_set_script_translations( $script_handle, 'itmar_guest_contact_block', plugin_dir_path( __FILE__ ) . 'languages' );
コピー このコードをload_plugin_textdomainと同様にinitアクションフックで実行します。wp_enqueue_scriptというコマンドを使います。このコマンドの第1引数で指定するのがスクリプトハンドルです。wp_enqueue_scriptで指定するのは他のwp_enqueue_scriptで使用するスクリプトハンドルと重複しない任意の文字列でよいのですが、wp_set_script_translationsで使うスクリプトハンドルは、すでにwp_enqueue_script等の登録コマンドで使用されている文字列でないとダメなのです。wp_enqueue_script等の登録コマンドを実行しておかなければいけないのです。
コードとしては次のようになります。
wp_enqueue_script(
'itmar_script-handle',
plugin_dir_url( __FILE__ ) .'dummy.js',
array( 'wp-blocks', 'wp-i18n', 'wp-element', 'wp-editor' ),
'1.0.0',
true
);
wp_set_script_translations(
'itmar_script-handle',
'itmar_guest_contact_block', plugin_dir_path( __FILE__ ) . 'languages'
);
コピー そんな無駄なエンキューしないといけないのかと思うのですが、これでwp_set_script_translationsは機能してくれているはずなのです。
とおもって、ブロックをリロードして表示を確認しました。${domain}-${locale}-${handle}.jsonまたは${domain}-${locale}-${md5}.jsonと書いてある記事を見つけました。itmar_guest_contact_block-ja-bb1d7dea005e67527e728d4801f74b61.jsonで後者の形式です。では、前者の形式にしてみようと思い、次のようにリネームしました。itmar_guest_contact_block-ja-itmar_script-handle.json
これで再度チャレンジ!
これで他のブロックも同じように国際化対応しようと思い、POファイルを作り、WP-CLIを実行しました。
調べた結果、WP-CLIはPOファイルから翻訳関数があったファイル名を読み取り、その名前をmd5ハッシュに変換してJSONのファイル名にしていました。そのため、POファイルに複数の元ファイル名が記録されていると、その数だけファイルが生成されます。
wp_set_script_translationsによるJSONファイルの指定(ようやく成功)
それから相当色々試してみました。po2jsonというパッケージも試しましたが、今一つしっくりきません。
function itmar_contact_block_block_init() {
$script_handle = 'text_domain_handle';
// スクリプトの登録
wp_register_script(
$script_handle,
plugins_url( 'build/index.js', __FILE__ ),
array( 'wp-blocks', 'wp-element', 'wp-i18n', 'wp-block-editor' )
);
//ブロックの登録
register_block_type( __DIR__ . '/build',
array(
'editor_script' => $script_handle
)
);
// その後、このハンドルを使用してスクリプトの翻訳をセット
wp_set_script_translations( $script_handle, 'itmar_guest_contact_block', plugin_dir_path( __FILE__ ) . 'languages' );
//PHP用のテキストドメインの読込(国際化)
load_plugin_textdomain( 'itmar_guest_contact_block', false, basename( dirname( __FILE__ ) ) . '/languages' );
}
add_action( 'init', 'itmar_contact_block_block_init' );
コピー このコードはこの公式ページ を見て考え付きました。wp_register_scriptというコマンドを使っています。これは先に紹介したwp_enqueue_scriptと違ってスクリプトファイルをエンキューせず、スクリプトハンドルだけを登録するコマンドです。これでスクリプトハンドルを確保します。register_block_typeでブロックを登録しますが、その時の登録情報の一つであるeditor_scriptを①で確保したスクリプトハンドルに上書きしています。wp_set_script_translationsを実行しているのです。
つまり、${domain}-${locale}-${md5}.jsonの形式のファイルが機能するためには、wp_set_script_translationsの第1引数は、ブロックのeditor_scriptに登録されたスクリプトハンドルである必要があるということです。editor_scriptに登録されたスクリプトハンドルというのはbuild/index.jsをロードするものでないといけません。それが上記のコードのwp_register_scriptというわけです。@wordpress/create-blockで作ったブロックのプロジェクトではブロックの登録はblock.jsonの情報に基づいて行われるようになっています。その中では"editorScript": "file:./index.js",となっています。wp_register_scriptは、それと同等の働きをするということがわかりました。その上でスクリプトハンドルを使い回すことができるようにするというのが、今回の成功への道のりだったと言えます。
もう一点忘れていけないのはPOファイルの翻訳関数の存在していたファイル情報にbuild/index.jsが含まれていないければいけないということです。src/edit.jsだけでは表示されません。これはPOTファイルの生成に関連するもので、PoeditでPOTファイルを生成するとうまくいきませんでした。
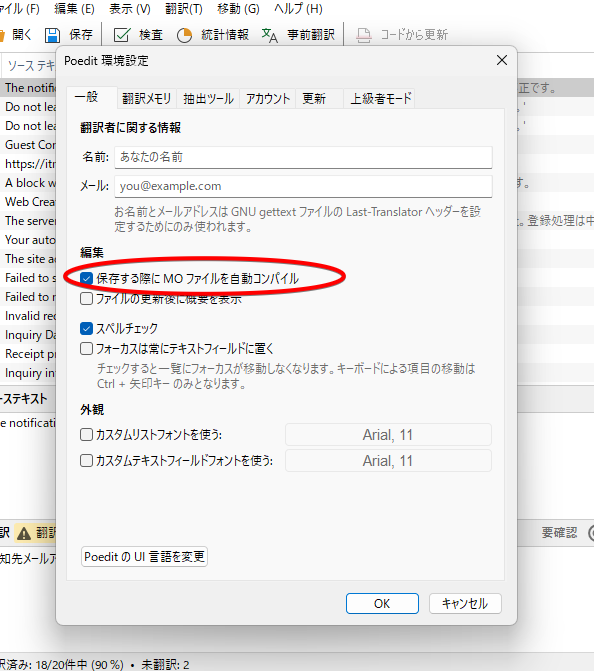
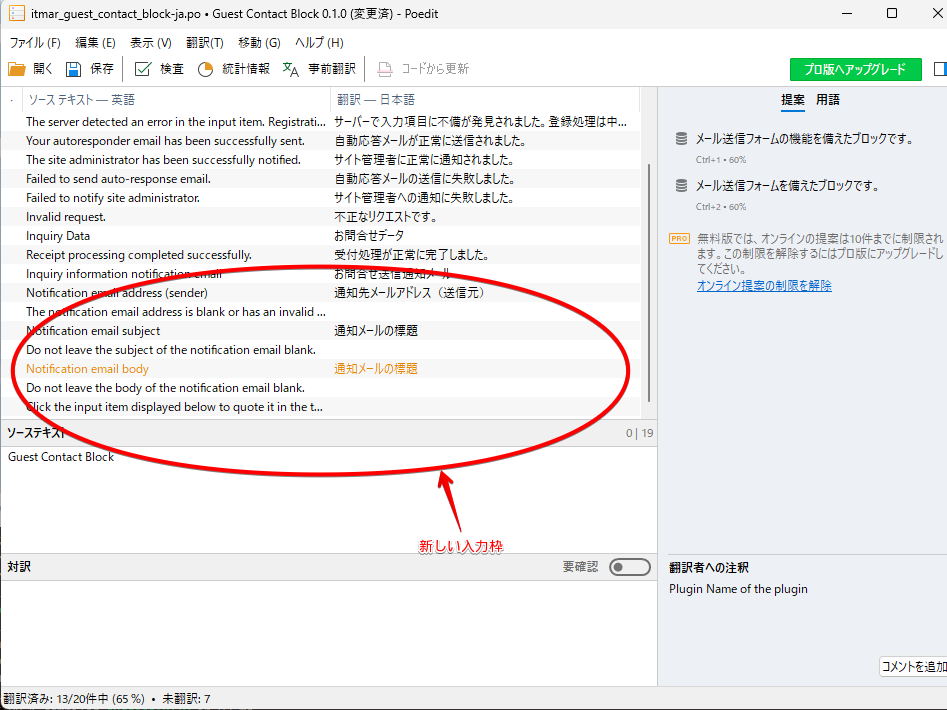
最後にPOファイルの更新方法を紹介します。これはPoeditの力を借りるのが一番だと思います。
wp i18n make-pot ./ languages/itmar_guest_contact_block.pot --exclude=node_modules/*
コピー それからPoeditを立ち上げます。
このように新しい入力枠ができています。ここに入力していくことで更新することができます。
この作業が終わってPOファイルを保存すればPoeditがMOファイルは更新してくれます。
wp i18n make-json languages/ --no-purge
コピー 長いブログになりましたが、以上にしたいと思います。














{kind=link}